文本类数据#
文本类(表格式)数据通常是指以行/列格式存储的数据。列(有时是行)通常由标题来标识,如果命名清晰,我们就很容易理解该行或列中的内容。
例如我们已经熟悉的.xlsx类型的文件,使用excel我们能打开编辑它们。
现在我们尝试用Python语言在平台上对xlsx,以及txt与csv进行读取和写入操作,大家看看就行,后续会有更全的实例,
通过这种方式,能够将读取数据和分析融为一体,并自动化整个流程,方便研究成果的复现。
有许多种读取文件的方式,我们可以不用任何工具包来打开数据,这是python自带的一种基本操作,即open()。我们也可以用工具包来打开,例如我们用pandas工具包来打开数据。后续介绍完Python编程基础后,我们会再针对这些内容进一步展开讨论,这里简单了解读写文件相关操作即可。
1 .txt与.csv#
首先我们用open打开一个txt文件
这个txt文件是从GRDC全球径流数据网站上选择一个站点,把txt下载下来的。这里我们选择了长江流域上的一个小流域杂谷脑(ZAGUNAO)流域。
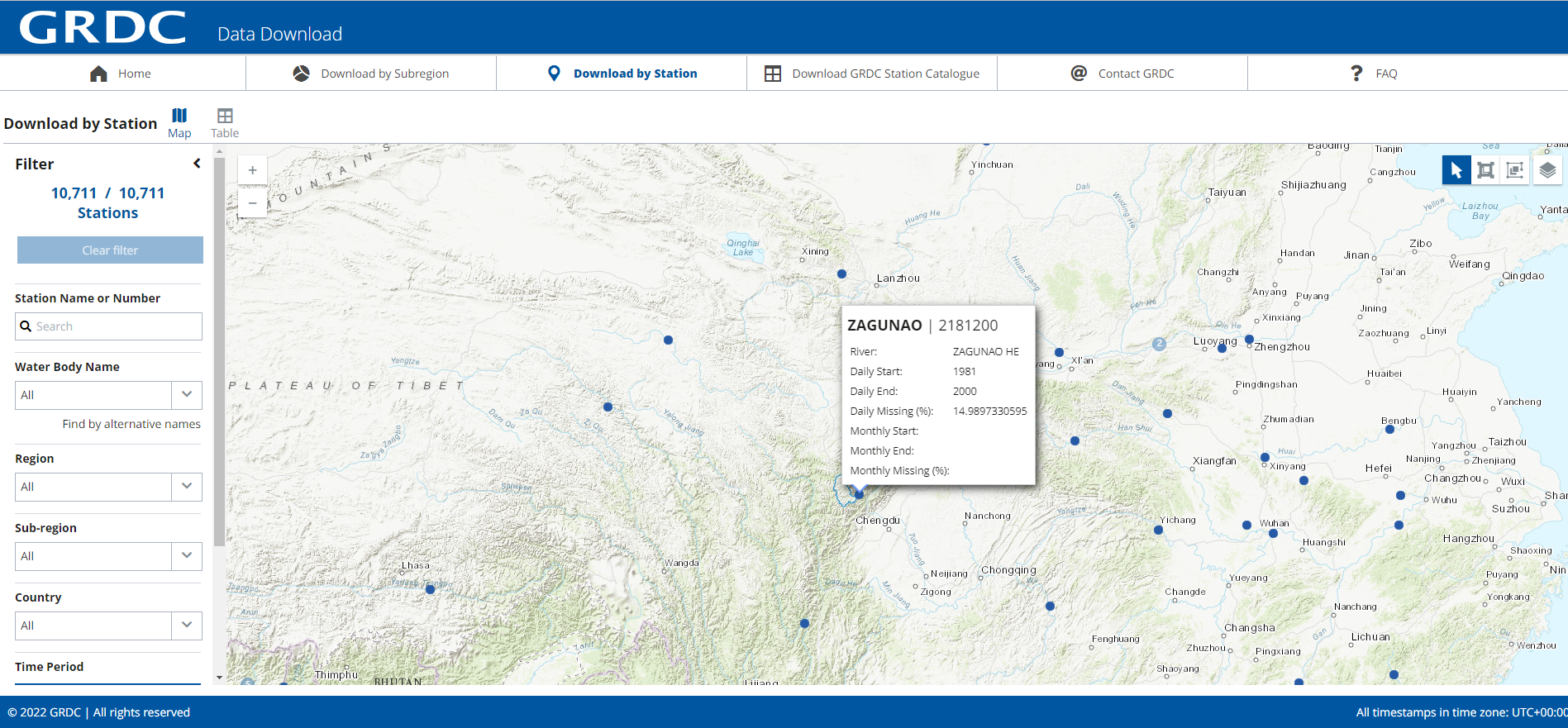
可以申请下载该站点的日径流数据,我们已经下载好了。
我们能看到数据格式就是txt格式:
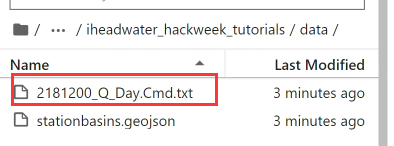
我们通过以下命令来打开文件:
file_object = open(filename, mode)
filename : 文件路径名
mode :告诉python我们对文件将执行读、写与追加等操作
mode包括:
‘w’ - Write Mode: 清空文件内所有内容,然后写入数据,从文件的开头处进行写入的。
‘r’ - Read Mode: 当文件中的信息只是为了被读取而不做任何改变时,就会使用这种模式。从文件的开头开始读取。也是打开文件默认形式,即不输入mode情况下,默认为r
‘a’ – 追加模式: 此模式会自动将信息添加到文件末尾。
‘r+’ – 读/写模式: 想对文件进行更改并从中读取信息时,使用此选项。文件指针放置在文件的开头。
‘a+’ - 追加和读取模式: 打开文件以允许将数据添加到文件末尾,同时读取信息。文件指针放置在文件的末尾。
这里我们用最简单的r模式来读取下载后简单处理的txt,我们会演示写内容到文件中,但一般不修改原始文件,所以我们接下来操作的是一个文件副本
#打开txt文件
file = open('../data/2181200_Q_Day.Cmd.txt','r')
注意路径采用了相对路径,相对路径:是指以当前文件资源所在的目录为参照基础,链接到目标文件资源(或文件夹)的路径。
在表示相对路径中,单点表示当前目录,双点表示上一级目录,反斜杠”/”表示分隔目录;
相对路径特殊符号有以下几种表示意义:
以”./”开头,代表当前目录和文件目录在同一个目录里,”./”也可以省略不写!
以”../”开头:向上走一级,代表目标文件在当前文件所在的上一级目录;
以”../../”开头:向上走两级,代表父级的父级目录,也就是上上级目录,再说明白点,就是上一级目录的上一级目录
以”/”开头,代表根目录
#关闭文件
file.close()
我们关闭一个文件后,就不能再访问它了,除非重新打开它。关闭后未重新打开,我们再读取的话,将出现一个异常:ValueError
file.read()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[3], line 1
----> 1 file.read()
ValueError: I/O operation on closed file.
在python中,打开和关闭文件的最佳做法是使用 with 关键字。
这个关键字会在嵌套的代码块完成后自动关闭文件。
#读取文件
with open("../data/2181200_Q_Day.Cmd.txt", "r") as work_data:
file = work_data.read()
如果我们想要写数据到txt文件中,可以用”a+”模式,即在末尾加内容。
但是通常我们不直接修改原始数据文件,所以如果我们想写入一些内容,比较好的做法是重新copy一个文件,然后在新文件里做修改。
import shutil
shutil.copy("../data/2181200_Q_Day.Cmd.txt", "../data/2181200_Q_Day.Cmd_modified.txt")
'../data/2181200_Q_Day.Cmd_modified.txt'
现在我们可以将Above is the full data追加到txt中
with open("../data/2181200_Q_Day.Cmd_modified.txt", "a+") as work_data:
file = work_data.write("\nAbove is the full data")
\n另起一行的意思
打开txt文件,下拉到最后一行,会发现我们写入的字句
接下来看看CSV (Comma Separated Values),CSV即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。
我们在国家地球系统科学信息中心下载黄河流域主要水文站汛期次降水数据集的样本,用于读写演示。
不过这里我们不再使用python原装的代码了,而是使用pandas包来帮助我们读取数据,pandas是python下很常用的一个包,后面我们还会介绍
import pandas as pd
csv_file = '../data/pre_test.csv'
csv_data = pd.read_csv(csv_file)
csv_data
| 站名 | 年-月-日 | 起 | 止 | 降雨量(mm) | |
|---|---|---|---|---|---|
| 0 | 北洛河大荔站 | 1990/6/7 | 1:00 | 2:00 | 0.1 |
| 1 | 北洛河大荔站 | 1990/6/7 | 2:00 | 8:00 | 8.6 |
| 2 | 北洛河大荔站 | 1990/6/7 | 8:00 | 11:00 | 0.6 |
| 3 | 北洛河大荔站 | 1990/6/10 | 19:00 | 20:00 | 0.1 |
| 4 | 北洛河大荔站 | 1990/6/10 | 20:00 | 1:00 | 2.6 |
| 5 | 北洛河大荔站 | 1990/6/14 | 7:00 | 8:00 | 1.5 |
| 6 | 北洛河大荔站 | 1990/6/14 | 8:00 | 9:00 | 3.6 |
| 7 | 北洛河大荔站 | 1990/6/14 | 9:00 | 14:00 | 0.5 |
| 8 | 北洛河大荔站 | 1990/6/14 | 14:00 | 18:00 | 0.2 |
| 9 | 北洛河大荔站 | 1990/6/17 | 11:00 | 14:00 | 3.4 |
| 10 | 北洛河大荔站 | 1990/6/17 | 14:00 | 16:00 | 1.1 |
2 .xlsx文件#
excel文件是大家最熟悉的了,用Pandas读取xlsx非常轻松,xlsx内容被读取并打包到一个DataFrame中,然后我们可以通过head()函数进行预览。这里简单介绍DataFrame是什么。
DataFrame 是一个表格型的数据结构。DataFrame 由三个部分组成:data、columns和rows。

data: 不同类型的数据。以后章节会接受python的数据类型
rows: 行标签,用于索引,从0开始
columns: 列标签,也是从0开始
DataFrame 为了方便我们读取、存储、编辑文件。现在我们读取我们下载好的.xlsx文件
import pandas as pd
df = pd.read_excel("../data/pre_test.xlsx")
df.head()
| 站名 | 年-月-日 | 起 | 止 | 降雨量(mm) | |
|---|---|---|---|---|---|
| 0 | 北洛河大荔站 | 1990-06-07 | 01:00:00 | 02:00:00 | 0.1 |
| 1 | 北洛河大荔站 | 1990-06-07 | 02:00:00 | 08:00:00 | 8.6 |
| 2 | 北洛河大荔站 | 1990-06-07 | 08:00:00 | 11:00:00 | 0.6 |
| 3 | 北洛河大荔站 | 1990-06-10 | 19:00:00 | 20:00:00 | 0.1 |
| 4 | 北洛河大荔站 | 1990-06-10 | 20:00:00 | 01:00:00 | 2.6 |
读取指定列
我们给read_excel()函数传递一个usecols参数,这个参数将根据选择的列进行读取文件
cols = [0, 1, 4]
students_grades = pd.read_excel('../data/pre_test.xlsx', usecols=cols)
students_grades.head()
| 站名 | 年-月-日 | 降雨量(mm) | |
|---|---|---|---|
| 0 | 北洛河大荔站 | 1990-06-07 | 0.1 |
| 1 | 北洛河大荔站 | 1990-06-07 | 8.6 |
| 2 | 北洛河大荔站 | 1990-06-07 | 0.6 |
| 3 | 北洛河大荔站 | 1990-06-10 | 0.1 |
| 4 | 北洛河大荔站 | 1990-06-10 | 2.6 |
读取过后,我们也可将 DataFrame 写入 xlsx 文件中。
import pandas as pd
df = pd.read_excel("../data/pre_test.xlsx")
df.to_excel("../data/pre_test_modified.xlsx", sheet_name="Sheet1", index=False, engine="openpyxl")
df_new = pd.read_excel("../data/pre_test_modified.xlsx")
df_new == df
| 站名 | 年-月-日 | 起 | 止 | 降雨量(mm) | |
|---|---|---|---|---|---|
| 0 | True | True | False | False | True |
| 1 | True | True | False | False | True |
| 2 | True | True | False | False | True |
| 3 | True | True | False | False | True |
| 4 | True | True | False | False | True |
| 5 | True | True | False | False | True |
| 6 | True | True | False | False | True |
| 7 | True | True | False | False | True |
| 8 | True | True | False | False | True |
| 9 | True | True | False | False | True |
| 10 | True | True | False | False | True |
以上就是对常见的文本类(表格式)数据与用Python对其进行读写的简介
接下来我们就来了解一下空间类型的数据